Psychological Sciences - Semantics Lab
Semantics Lab

General Background
The act of reading is converting a visual pattern into meaning. Most people read effortlessly every day, but how is this achieved? To answer this question, our lab uses a very multidisciplinary approach that includes elements of computation, information theory, behavior and neurophysiology.
Sometimes context provides useful clues to what the next word will be. In cognitive psychology, this is often explored using the lexical decision task with a prime word (e.g., “CAT”) preceding a target word (e.g., “DOG”). If the prime alters the speed with which the target is recognized, then we infer that the mental representation of the prime and target words interact in some way. Priming can occur between two words that are semantically linked, but it may also occur because one word frequently co-occurs in text withanother word. One current research focus in the lab is the measurement of word-word and word-sequence co-occurrences with large samples of text (Brants and Franz’s (2006) terabyte Google Dataset). Based on these measurements, we are examining how expectancy generated from a word or word sequence facilitates recognition of a subsequent word.
Recentand continuing advances in computationally processing written language, or natural language processing (NLP), can reasonably be described as producing society-level changes. Representing word meanings as vectors in an embedded space while still appropriate in some problem spaces has been replaced with AI architectures using information ranging from the character level to the document document. Spelling correction is ubiquitous and ChatGPT can write a better paragraph than your college roommate. We use these tools to query large documents, and gain insight into how patterns of writing reveal aspects of the authorwho wrote the text.
We also have a general interest in developing algorithms to solve interesting problems that are typically associated with human behavior.
Recent and ongoing projects include:
- Large Language Models (LLM) - Can ChatGPT be the ultimate free association participant?
- Develop software to evaluate EEG data using a novel algorithm for identifying repeating signals such as blinks.
- Deception - identifying deceptive language
- Social Justice/Dog Whistles - we use AI/Machine Learning to detect hidden messages for a target audience
- Computer Vision - recognizing handwritten characters and making inferences about the author based on writing style
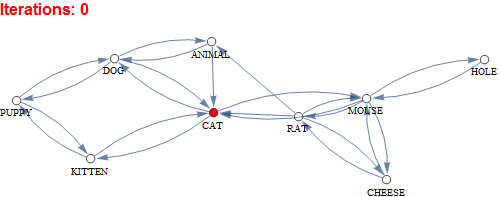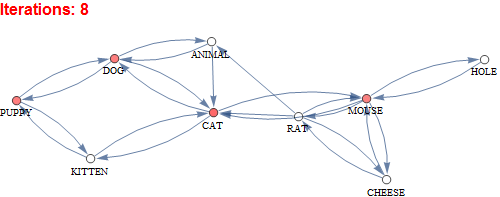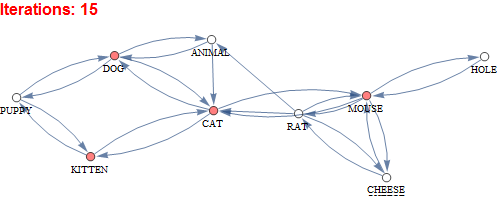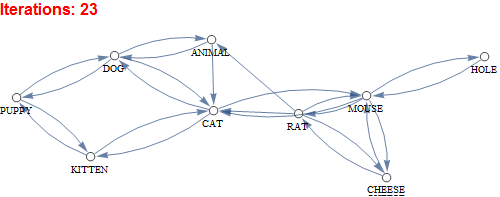
What is this network?
This network is a spreading activation model that begins at iteration 0 with stimulation of the CAT node that spreads through connections across the network activating other nodes. Activation dissipates with time until iteration 23 has only a negligible activation level in any of the nodes.
Some of the links on this page may require additional software to view.